Sprint Commitment - it is only in your head
It’s common for Scrum-like teams to be upset when they don’t fulfill their sprint commitments. But should they? Is it that important to finish everything by the end of the iteration? Commitment is very attractive as a tool to exert pressure on the team, but if used beyond that it takes more than it gives. E.g. often we dedicate whole meetings spending many man-hours just to argue about why we didn't complete all the activities "in time". Hopefully by the end of the article you’ll be convinced that fulfilling sprint commitments in time is actually ineffective and shouldn't be pursued by managers.
Precise estimates are not precise
So let’s say we estimate in hours and we decide that one of our PBIs (Product Backlog Item) will take 10 hours to be done. Do we really mean it’ll take exactly 10 hours? No. Given we’re good at estimating it’ll take us something like 8-12 hours. So there is going to be some deviation. But we keep going and by the end of the planning we decide to take many stories for 320 hours in total. But wait a sec.. Doesn’t that mean that we just gave a precise estimate (320 hrs) based on not-so-accurate values (8-12 hrs)? This doesn’t seem right. Something like 260-380 hrs would sound more trustworthy.
Incidentally a very nice book How to lie with statistics mentions this kind of overly precise results as a very good indicator that someone’s lying. Takeaway: your estimate cannot be more accurate than the data it’s based on.
Okay, we’ve learnt our lesson - no more pretending. We’ll mitigate the error effect by introducing Story Points (SP). Since they are less granular than hours the final estimate in 36 SP would in reality mean something like 260-380 hours of work. Which seems right now. So in a sense by using less precise units we made our final estimates more accurate. Just think of it: now we don’t spend as much efforts on estimating (since we don’t need to be too precise) and we achieved better results. Sweet!
But here is something we forgot - the sprint length is still (let's say) 2 weeks which still translates into hours. We don’t measure sprint length in SPs - it’s still measured in time. Thus using SPs doesn’t actually impact the success of the sprint as some SP advocates think.
Risk mitigation requires huge amount of additional resources
Now, if you're asked to give your best estimate - you'll probably try to end up somewhere in between "too early" and "too late", right? This means that our "best shot" implies 50% risk of failure. That's too much of risk - half of the time we'll be late.
If our goal is to finish the sprint in time, we have to leave some additional room for pessimistic scenario. This can lower the odds of failure. But how much room do we need? As pointed by Goldratt in his Critical Chain the accuracy of the estimates looks like this (see Probability Density Functions if you have difficulties reading this graph):
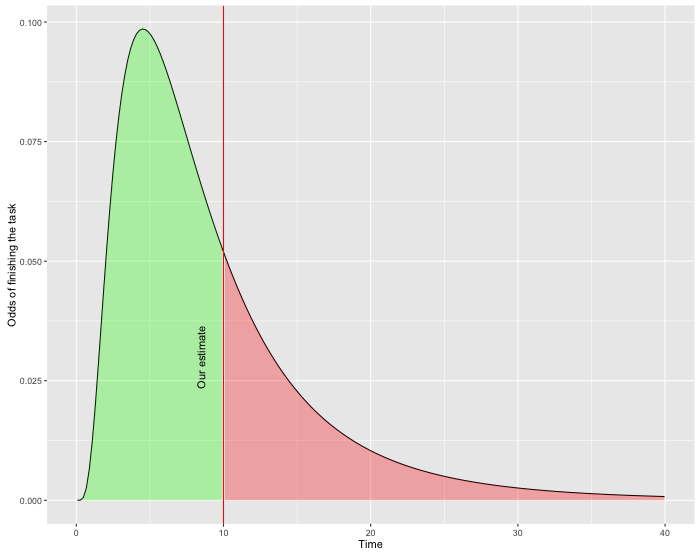
As mentioned on the graph - 10 hrs is our best shot for the estimate. And there is 50% chance that the task will be finished earlier (to the left) and another 50% chance that it’ll take more time (to the right). But see how skewed it is - this is because our left part is limited by 0 (no task can take 0 min or less). But there is no such limit on the right - if we missed something during the estimate, it can easily take 20 hours to finish. And even 50 hours is on the table - sometimes we make big mistakes. So while the lower boundary is limited by 0, the upper boundary is not really limited - there is always a probability of something really bad happening.
Now back to our problem - we want to mitigate the risks and leave some buffer in the sprint. So given the probability distribution above, here is what would be the 60% mark (still 40% chance of finishing the tasks late):
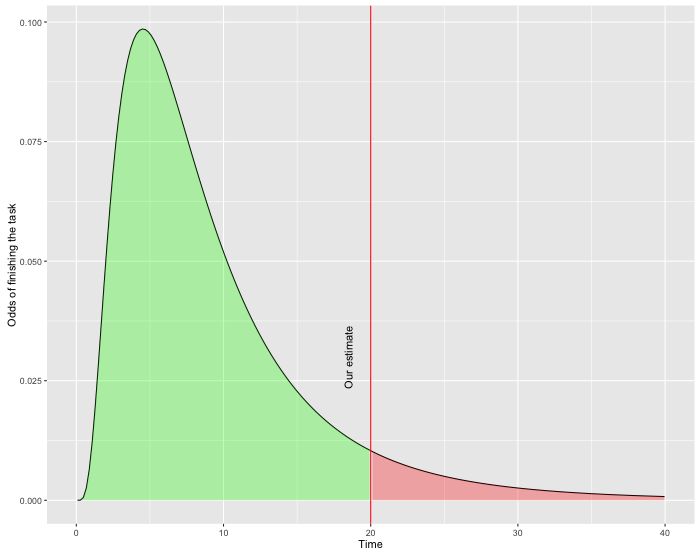
While we increased the probability of success by 10% the estimate increased from 10 to 20hrs (+100%)! In reality the numbers would depend on the level of uncertainty you’ve got during estimation. But the tendency will be similar - while you add some safety net to mitigate the risks of being late (N), you’d need to multiply your estimates by some bigger factor (N+).
So we figured that adding a safety buffer is a tough choice. If you really want to be on safe side, you have to present a huge ETA to be sure you’ll finish the task in time. I hear people around using magic formulas like “multiply your estimate by 2 and add another 10%” or something like that. We just found out why it works that way.
All team members matter
But that’s not the last sad thing about the estimates. Remember - it’s only when all of the PBIs within the iteration are finished we assume the sprint completes successfully. Otherwise our famous Burndown Chart is not going to touch 0. But don’t forget that we have more than 1 person working on the sprint. If we have 4 of them, they will do some work in parallel.
Let's consider the worst case scenario first: PBIs are assigned to people at the start of the sprint. If
every person has 0.5 chance
to finish his tasks in time, then the odds of all of them finishing successfully is:
0.5 x 0.5 x 0.5 x 0.5 = 0.0625. This is because they work independently and have their "own
sprint backlog".
In reality we don’t (hopefully) assign tasks in the start of the sprint. Team members take tasks from the shared pool - if person1 finishes his task earlier, he can grab next task from the pool. But some work cannot be shared:
- Sometimes there are activities that only particular people have expertise in.
- Also by the end of the sprint you’re left with 4 open tasks assigned to 4 available developers. These tasks are truly independent and any of them can arrive late. And what if there are 8 members? Do you really think all of them will finish in time on the last day provided they all have 1 task in progress?
So even if this factor is not very big, it still has some negative effect when it comes to the commitments.
Overestimating can be counterbalanced by human factor
Armed with this knowledge let’s run a successful sprint. Now it’s easy:
- We keep the number of people as low as possible
- Estimate all the PBIs and then multiply all the estimates let’s say by factor of 3.
But while this simplifies our goal, it doesn’t guarantee anything. Even if we raise our odds - they never reach 100%. So some sprints will still fail. And even more frequently than you'd think. This time - not only because of the probabilities, but because of human factor.
When we’re too liberate to the team, they relax too much. If people have a lot of free time, they feel that they can work slowly and make it anyway. And thus people slack. Well, at least I do he-he. Alternatively they start improving the software beyond the required level (you can do this forever). So all the buffer we introduced by multiplying estimates is going to be eaten by this reckless behaviour.
Hence not only we need to work on the estimates, we also need to apply some pressure to the engineers. Previously when they were in rush because of close deadlines it was a natural thing - you didn’t need to do anything. Now you should come up with something else for the sprint to succeed.
Finishing Early is not the same as Finishing Timely
But let's imagine you did it - you finished multiple sprints in time. Unfortunately now there is even a bigger problem - sprints finish too early. So you either need to change the scope of the sprint right in the middle (which ironically may itself fail the sprint) or you need to finish the sprint earlier. The latter would result into floating sprints which is not necessarily a bad thing, but prepare to say bye-bye to the regular "same time, same place" meetings.
Let's recap - it was sad when we were late, so we fixed the "problem" by overestimating. Now we're too early and we're even sadder. So by mitigating the risks of finishing late we increase the risk of being too early. What a dilemma!
After all this
Overall there seems to be too much fuzz around sprint commitment and Burndowns. But sprint is a tool, not a goal. Neither we work for nice metrics. Our job is to create and maintain products. If this function is impaired just to make the charts green, it means we shift our priority from the product to the metrics.
Finishing all the PBIs on the last day of sprint is almost an impossible mission. You always will be either earlier or later. So you can either choose the hard way - fighting with variability, overestimating and spending a lot of energy to be in time. Or you can concentrate on creating a successful product and stop paying attention to imaginary problems.